How We Built More Than 100 Customer Success-Integrations for our Product

If there is one thing that sets Akita apart from its competitors in Customer Success software, it is our ability to ingest data from virtually any data source a customer may have. This includes:
- Visitor behavior captured by our Javascript SDK or Segment.com;
- Customer data sent to Akita using our RESTful API;
- 3rd-party integrations using publicly available APIs;
- Cloud databases and data warehouses; and
- Even retrieving data from a customers own API.
If the data is out there, Akita can usually import it and use it to transform your Customer Success department into a well oiled machine!
But writing integrations are hard! How do you do it?
It is hard.
And things can get very complicated if you let them.
We succeeded by starting with a simple pattern that works for most integrations and then adding the ability to override this pattern through additional configuration on a per-Provider and per-customer basis.
The Model
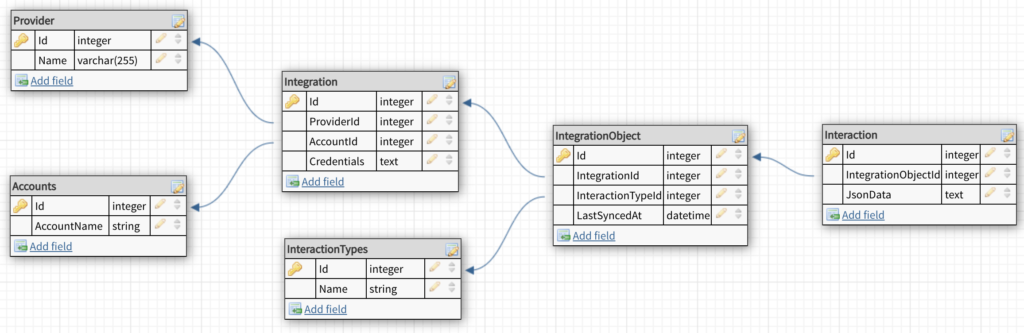
We have a few terms at Akita we use to describe our data model:
Provider.This is the source of the data. In most cases this is a SaaS application (Salesforce.com, Zendesk, Intercom, etc) but also includes “Customer-provided Data”, cloud-accessible databases (Windows Azure, MySQL, Postgres), data warehouses (Redshift, BigQuery), customers own REST APIs, etc.
Interaction Type. Akita is a Customer Success Management platform and we typically ingest specific types of data (Accounts, Contacts, Deals, Tickets, Tasks, etc). We call these Interaction Types. We also provide the ability to retrieve custom Interaction Types.
Integration. This is the connection between an Akita customer and a Provider. ie. “Our Salesforce Instance”. Our customers authorise the connection using OAuth (when possible) or API tokens.
Integration Object. An Integration Object is the relationship between an Integration and an Interaction Type. One example is “Accounts from your Salesforce instance”.
Interaction. This is a single instance of an Integration Object. For instance, it might be a “Company XYZ from Salesforce” or a specific support ticket in Zendesk.
The Process
Once you have authorized an Integration between Akita and a Provider (usually a 3rd-party SaaS app), there is a 3-step process that runs constantly: schedule, retrieve and process (and REPEAT!)
Schedule
In most cases, Akita syncs your data multiple times throughout the day.
The Scheduler runs continuously and finds those Integration Objects that require syncing. This takes into account their defined sync frequency (how many times per day) and the time that has elapsed since the last sync. Any Integration Objects that require syncing are then sent to the Retriever.
Not all Interaction Types are created equal. Some must be synced more frequently than others and some integration partners have higher API limits. We can sync data more or less frequently on a per-Provider / per-Interaction Type basis depending on the limits of the Provider and the needs of each customer.
Retrieve
The Retriever is responsible for connecting to the Provider and, well, retrieving the data. We spent quite a while coming up with the name. The Retriever itself is relatively simple. It:
- Requests any data that has changed since the last successful sync;
- If the request fails due to out-of-date oauth credentials, it will refresh the token and try again;
- Otherwise, it checks if the request was a success or a failure.
If the request was a success, it:
- Passes each retrieved Interaction to the Processor; and
- Updates the “Last Synced At” property of the Integration Object.
If it was a failure, it:
- Logs the reason;
- Alerts Akita as well as the customer; and
- (When appropriate) disables the Integration.
Process
When Interactions are retrieved successfully, Akita must analyze each Interaction. The Interaction Type (an email, an ‘Account’ record, a deal, etc) determines what must be done with each retrieved Interaction. The Processor is responsible for several things:
- It stores the Interaction in our database—over a few related tables;
- If the Interaction is an ‘Account’ or ‘Contact’ record, it attempts to match it to an existing Account or Contact record in Akita; or
- If no matches are found, it may need to create a new Account or Contact in Akita.
No real magic here. Nothing mind-blowing. No secret sauce. Just a solid foundation that can be extended to build integrations with almost any kind of data source we need.
In the next few posts, I’ll dive deeper into each part of the process and point out a few things that might trip you up if you are going to write your own integrations. We’ll look at how we accomodate different types of authentication, how we handle errors, how we make data accessible to our users, and more. Stay tuned!
Update: Part 2 is out! How Frequently Our Customer Success Application Syncs Your Data
